
Performance of Signia AX in at-home listening situations
Due to the restrictions dictated by the COVID-19 pandemic, a fully remote study of Signia AX was done in collaboration with Hörzentrum Oldenburg in Germany, involving both fitting and assessment of Signia AX being done in the participants’ own homes. The results showed high levels of immediate satisfaction with AX just after the fitting, and in an at-home speech-in-noise test, the new Augmented Focus processing allowed the participants to perform significantly better with AX than with their own hearing aids.
Created Updated
Written by Niels Søgaard Jensen, Claudia Pischel, Brian Taylor, Michael SchulteIntroduction
The new Signia Augmented Xperience (AX) platform and, specifically, the new Augmented Focus™ technology were developed to be used in a vibrant world with widely varying and challenging communication demands. However, social distancing measures caused by the COVID-19 pandemic severely challenged researchers’ ability to assess and demonstrate the benefits of Signia AX. The lockdown, for example, made it temporarily impossible for researchers to ask test wearers about relevant listening situations like busy restaurants or social gatherings where hearing aid wearers often struggle to understand speech (Picou, 2020). Further compounding this challenge, many of the research laboratories that assess hearing aid performance under controlled lab conditions were closed.
Fortunately, the pandemic sparked some creative thinking, and alternative test methods emerged, many of which relied on virtual interaction and telecare. Given the research constraints associated with the pandemic, we decided to run a study where data were gathered in the most common listening situation of the past year: the wearer’s own living rooms.
This article reports on the results from this study. These results show superior performance and high levels of immediate wearer acceptance of Signia AX in a typical at-home listening situation. Before discussing this study, let’s review the Augmented Focus technology and how it differs from other types of signal processing found on conventional hearing devices.
Signia AX and Augmented Focus
Augmented Focus, which is a new and fundamentally different approach to sound processing in a hearing aid, is found on the new Signia AX platform. The basic underlying concept of Augmented Focus is to improve the wearer’s access to speech by increasing the contrast between speech and the other sounds surrounding the wearer. Increasing this contrast supports the brain in performing an auditory scene analysis (Bregman, 1990) by specifically easing the process of auditory stream segregation. Auditory stream segregation is a process in which the brain separates different sounds from each other to improve perception. This could, for example, be separation of a speech signal from a background of noise, which would allow the listener to better understand the speech.
The main principles in the Augmented Focus processing are illustrated below in Figure 1.
A technological cornerstone of Augmented Focus is Signia’s unique beamformer technology, which is used to split the incoming sound into two separate signal streams. This is shown in left part of Figure 1. One stream contains sounds coming from the front of the wearer, while the other stream contains sounds arriving from the wearer’s back and sides. To optimize the listening needs of the wearer, the two streams are processed separately from one another across 48 channels.
Augmented Focus uses two dedicated processors to analyze the characteristics of sound in each stream. This unique approach allows one stream to be processed as a Focus stream where the aim of the processing is to optimize speech clarity and intelligibility. In contrast, the other stream is processed – completely differently – as a Surrounding stream. The rationale of this split processing is twofold: 1) Provide a clear and stable perception of the wearer’s soundscape, and 2) Introduce a large contrast between the Focus stream, which is usually sounds coming from the front of the wearer, and the Surround stream, often sounds coming from the back and sides. The latter rationale typically provides wearers with more compression and more aggressive noise reduction for sound coming from their back and sides. In the example shown in Figure 1, the Focus area is in front of the wearer.
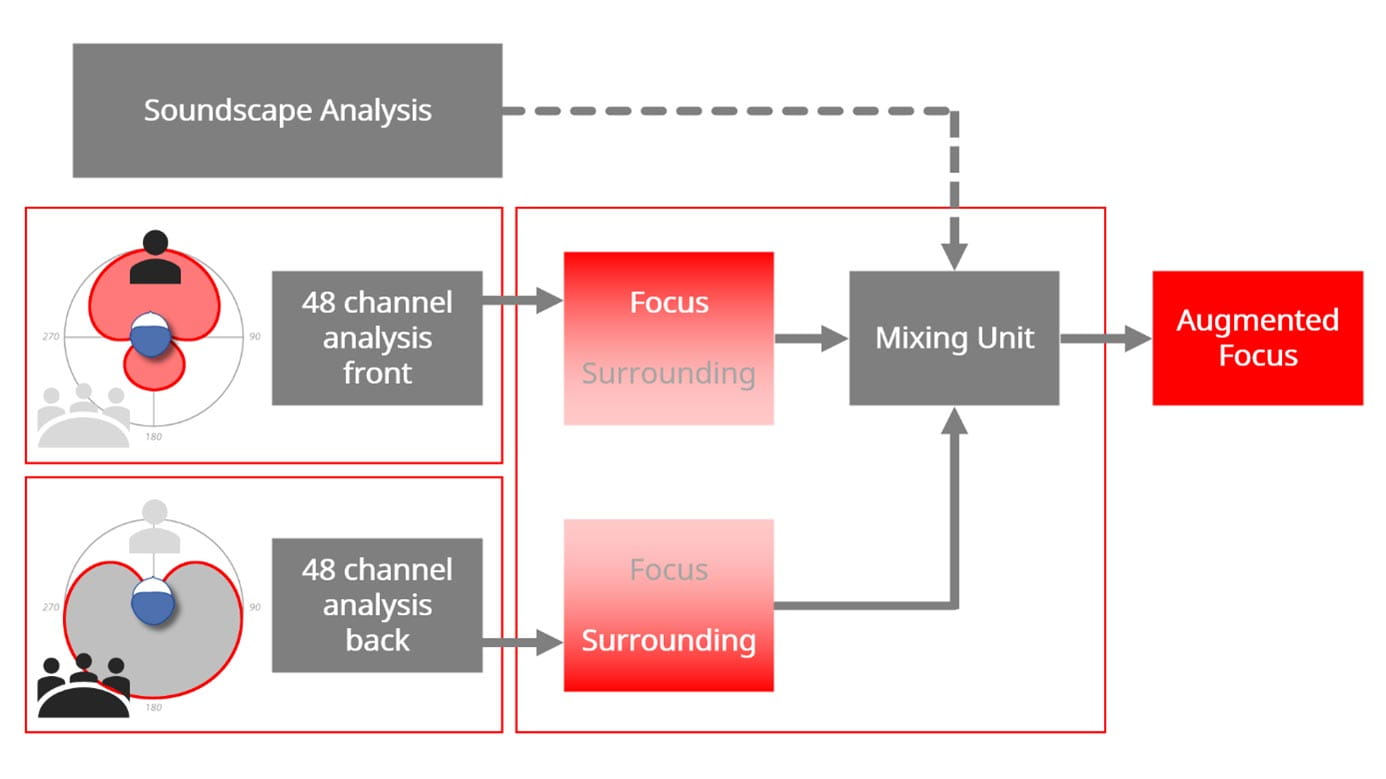
Figure 1. Schematic diagram showing the main processing blocks in Augmented Focus. Beamformer technology is used to split incoming signals into two streams, which are processed separately. In this example, the speech coming from the front is detected and processed as a Focus stream, while the noise from behind is detected and processed as a Surrounding stream. The streams are mixed intelligently based on a soundscape analysis
The two streams are recombined in a mixing unit, which takes the information provided by the advanced Dynamic Soundscape Processing analysis into account. The Dynamic Soundscape Processing analysis was launched as part of the Xperience platform in 2019 and includes sound classification, motion sensor, signal-to-noise ratio estimation, Own Voice Processing, and determination of ambient modulations (Froehlich et al., 2019a; Froehlich et al., 2019b; Froehlich et al., 2018). More information about the Augmented Focus processing is provided by Best et al. (2021).
Because the Focus stream and the Surrounding stream are processed separately, there are several significant wearer benefits. One, when a speech signal is in the Focus stream, it is processed and fully optimized for speech alone without being affected by sounds in the Surrounding stream. In comparison, a conventional processing scheme triggers its noise reduction algorithm when a loud noise in the background is detected, thereby reducing the gain for all signals, including the speech the wearer wants to hear.
Two, with separate processing of the two streams, Augmented Focus provides more dedicated and stable processing for speech. For sounds in the Focus stream, it provides more linear processing which makes the speech clearer, and thus, prominently stand out from the background noise, which is more attenuated and typically processed with more compression.
Three, the split processing improves the perception of the background sounds by offering a fast and precise adjustment of the gain for sounds in the Surrounding stream. This feature of Augmented Focus improves the stability of the background noise and, in turn, the wearer’s entire soundscape is enhanced because of this unique split processing. This effect is comparable to how an audio engineer mixes the sound for a movie. Separate recordings of voices and background sounds enable the audio engineer to mix the sounds in a way that creates a contrast between the voices and the background effects. This engineering feat enables the audience to understand speech while simultaneously maintaining a clear perception of the background, even in a scene with loud background noises.
The way Signia AX was tested in this study may not be compared to a loud and action-packed scene in a fast-paced movie, but the study was able to demonstrate many of the benefits of Signia AX with Augmented Focus technology – a device designed to be used under all sorts of listening conditions, including calmer circumstances than those found in the latest scene of a Fast and Furious movie!
Methods
Participants
Twenty people (10 male, 10 female) with a mild-moderate hearing loss participated in the study. Their age ranged between 59 and 78 years, with an average age of 71.3 years. While audiograms were available for all 20 participants, not all of their audiograms were recent. Since a new audiogram could not be obtained due to the COVID-19 lockdown, it was decided to measure the InSituGram for all participants and use this for the fitting of the Signia AX devices. The InSituGram is the option available in the Connexx fitting software to measure pure-tone hearing thresholds with the hearing devices worn on the ear by the wearer. It provides an estimate of the standard pure-tone audiogram, gathered in the clinic using earphones. Figure 2 shows the mean InSituGram for the 20 study participants. All participants were experienced, bilaterally fitted hearing aid wearers. Their own hearing aids were of various brands and models, and the age of these devices ranged between zero and seven years, with an average age of three years. To establish a real-life communication situation during the at-home assessment of Signia AX, participants were required to live with another person.
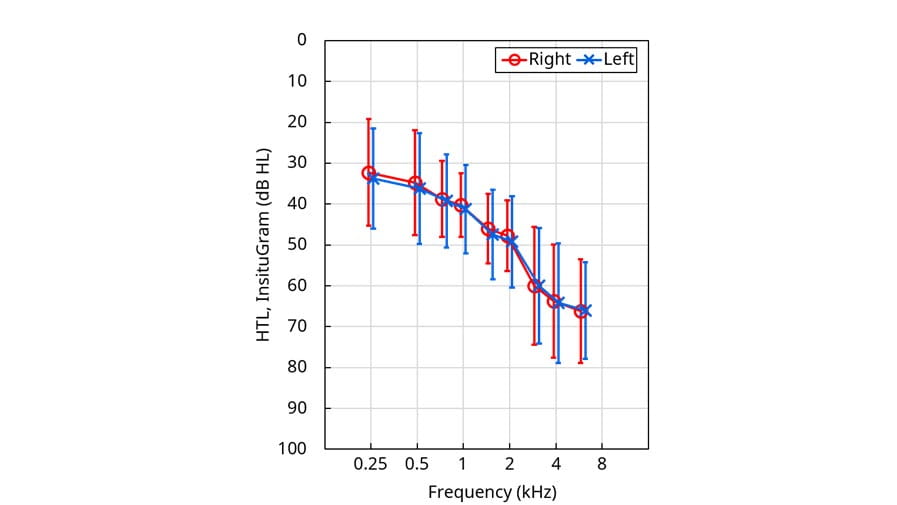
Figure 2. Mean pure-tone InSituGram values for the left and right ears of the 20 participants. The error bars show ± one standard deviation.
Remote Setup
Due to COVID-19 protocols, no in-person meetings with the participants could be conducted, and all interaction occurred remotely. The participants received a so-called test suitcase, delivered to their home address, with all equipment needed to participate in the study including a pair of Signia AX Receiver-In-Canal (RIC) test devices and necessary accessories, a tablet computer for online communication (e.g. remote fitting and interview administration of questionnaires), loudspeakers and other equipment needed to establish a setup for speech testing (see Figure 3).

Figure 3. The test suitcase that all participants received from Hörzentrum Oldenburg, including all necessary equipment for remote fitting and testing of the Signia AX hearing devices.
Fitting
The Signia AX test devices were fitted remotely using the Connexx fitting software. This arrangement allowed the fitter access to all the options available in a normal fitting conducted in the clinic. The InSituGram was measured on both ears and was used for the calculation of the prescribed gain settings, which were based on the new AX First Fit rationale. Fine-tuning of the devices was kept to a minimum. In just two cases, minor adjustments of master gain were done. In the remaining 18 cases, the prescribed gain setting was used throughout the duration of the study. All the RIC devices were fitted with either vented or closed ear sleeves.
Immediate Acceptance Test
Immediately after being fitted, the participants answered a list of questions, read aloud by the experimenter. The participants were asked to rate various aspects of their immediate perception of and satisfaction with the Signia AX devices. The questions focused on the participants’ perception of speech and their own voice, various audible artifacts, and their overall satisfaction with the devices. In the analysis of the participants’ ratings, questions were combined to address specific topics, e.g. one mean rating of speech loudness was obtained by averaging ratings of three loudness-related questions. All ratings were conducted using a four-point scale, but to simplify interpretation, all ratings were transformed to a linear 0 to 10 scale. When combining and reporting the mean ratings, high ratings on the linear scale equate to high levels of listener satisfaction.
Listening to the speech of another person is a central element in this study design. Therefore, study participants rated the speech of familiar voices. In one case during data collection, a participant was alone at the time of the testing, and speech ratings of familiar voices were not completed by this participant. However, the other questions unrelated to the speech of familiar voices were rated.
Speech in Noise Test
To allow an assessment of speech intelligibility in noise, a new test approach developed by Hörzentrum Oldenburg was used in this study. This enabled for speech in noise testing to be conducted in the participants’ homes. Under supervision of the researcher, the participants established a test setup consisting of two loudspeakers, one mounted on the test suitcase, which was placed on a table in front of the participant, and the other loudspeaker placed on the backrest of a chair behind the participant (see Figure 4).

Figure 4. The setup used for the Oldenburg sentence test. Stimuli are presented from two loudspeakers placed in front of and behind the participant. A microphone mounted on the top of the participant’s head monitors the sound pressure levels presented.
The participant was sitting on a chair between the loudspeakers, with a distance of approximately 1.5 m to each loudspeaker. Using a special headband, a microphone was mounted on the top of the participant’s head, allowing for calibration and constant monitoring of the level at the listening position, and allowing for correction of the recorded signal-to-noise ratios if the participant moved during the measurement, or if external noise occurred. The speech test used was the German Oldenburg sentence test (OLSA; Wagener et al., 1999). The speech signals used were five-word sentences constructed by words spoken by a male speaker. During the test, a speech-shaped unmodulated noise was played from the back loudspeaker at a constant level of 65 dB SPL. The task of the participant was to repeat the sentences. After each sentence, the number of correctly repeated words was scored by the researcher, and the sound pressure level of the next sentence was adjusted adaptively. The outcome of the test was the Speech Reception Threshold (SRT), defined as the signal-to-noise ratio where 50% of the words could be correctly repeated. The speech test was performed with both the Signia AX devices and the participants’ own hearing aids.
Results
The results of the immediate acceptance test are summarized in Figure 5. With no mean ratings below 8 on the transformed 10-point scale, it is evident the general immediate satisfaction ratings were favorable. Examining each of the different domains or attributes, it is, of course, striking that mean scores of 10 were observed for “Internal noise”, “Artifacts” and “Feedback”. Thus, all 20 participants provided the highest possible rating for all questions within these domains, suggesting the immediate acceptance of the Signia AX devices will not be hindered in any way by such issues.

Figure 5. The mean ratings of immediate acceptance made by the 20 participants. For all dimensions/attributes, a high rating indicates a high level of acceptance. The three upper ratings (of speech) are based on N=19.
Another noteworthy finding is the extremely favorable ratings of speech (loudness, sound quality and intelligibility). These ratings were made based on real-life communication with a conversation partner who was present during the at-home session. Results indicate that participants rated the speech of their at-home partner to be clear and easy to understand. Further, these ratings strongly indicate that the Signia AX processing optimizes the overall subjective quality of the speech signal in an at-home listening situation. Note that all mean ratings were above 9, and the mean rating of speech intelligibility reached 9.8, with all 19 participants providing an individual mean rating higher than 8.0, indicating excellent performance. Because mean ratings of loudness and sound quality of speech were slightly lower, with 16 out of 19 participants (84%) and 15 out of 19 participants (79%) having individual ratings above 8.0, these results might be associated with the fitting approach used in the study in which fine-tuning of gain was kept to a minimum. Only some minor overall gain adjustments were performed for two out of the 20 participants. Based on comments made by some participants after the assessment, it can be assumed that some of the suboptimal loudness and sound quality ratings could have been improved further by fine-tuning.
The ratings of the listeners’ own voice domains (loudness and sound quality) also indicated a high level of satisfaction. This may be attributed to the Own Voice Processing (OVP) technology, integrated in the Augmented Focus processing. The individual data showed that 17 out of 20 participants (85%) provided ratings in the upper end of the scale, indicating listener satisfaction with their own voice. This finding is consistent with results from a previous OVP study (Froehlich et al., 2018). This favorable level of listener satisfaction was obtained using vented and closed ear sleeves. The new EarWear 3.0 collection of eartips and sleeves, included with Signia AX, offers wearers a choice of both more open and more closed coupling and could provide even more favorable listening satisfaction ratings for the sound of their own voice. Additionally, based on comments from some participants, the chosen couplings were not optimal in all cases, and this may have affected the participants’ own voice ratings and could explain why the mean rating of own voice sound quality (8.2) is the lowest rating in Figure 5.
Taken as a whole, even though there were limitations caused by the coupling and lack of fine-tuning, a mean overall satisfaction rating of 8.7 – and 19 out of 20 participants (95%) reporting to be satisfied with Signia AX – indicates these issues associated with fitting remotely during the pandemic are largely inconsequential and have not detracted from the highly favorable first impression of the Signia AX.
This study also evaluated the participants’ ability to understand speech in the presence of noise using the Oldenburg sentence test. The participants were tested in the at-home environment both with the newly fitted Signia AX and with their own hearing aids. The left panel in Figure 6 shows the mean SRTs for own hearing aids compared to the Signia AX. With their own hearing aids, the mean SRT was -5.17 dB, while it was -6.93 dB with Signia AX. Thus, Signia AX offered a substantial speech-in-noise performance benefit of 1.8 dB, which is statistically significant according to a paired t-test (t(19) = 4.66, p = .00017).
The 1.8 dB difference in SRT corresponds to more than 25% improvement in speech intelligibility in noise, when the SRT difference is converted to a difference in speech intelligibility in percent, using the slope of the psychometric function of the Oldenburg sentence test for subjects with hearing loss reported by Wagener & Brand (2005).

Figure 6. Left panel: Mean SRTs for own hearing aids (HA) and for Signia AX in the Oldenburg sentence test, based on data from 20 participants. The error bars indicate one standard deviation. Right panel: The individual differences between Signia AX and own hearing aids. A positive benefit of Signia AX indicates a lower (better) SRT.
Another noticeable observation is the rather large individual variation in SRT across participants, with standard deviations exceeding 3 dB. Besides natural inter-participant variation in performance level, some of this variability is likely related to the fact that testing was conducted in the participant’s homes where considerable acoustic variability between participants is expected.
A plot of the individual SRT benefits of Signia AX compared to own hearing aids is shown in the right panel of Figure 6. The plot shows that 17 out of the 20 participants (85%) performed better in the test with Signia AX than with their own hearing aids. One participant performed at the exact same level with both sets of hearing aids, while only two participants performed better with their own hearing aids. In two cases, the benefit from the Signia AX exceeded 3 dB, but the typical benefit was between 1 and 3 dB SNR.
Discussion
While it is essential to evaluate all new hearing devices in carefully controlled laboratory conditions, that was not feasible during much of the COVID-19 pandemic. This study demonstrates that accurate and reliable data can be collected while participants remain home.
There are advantages to conducting an at-home study of hearing aid benefit. In this study, the hearing devices were tested in conditions where the participants would use them in their own real life, interacting with familiar voices and doing ordinary daily activities. Asking participants to evaluate new hearing devices in a listening environment they are familiar with – outside the sterile and contrived environment often experienced in a lab – could possibly add additional ecological validity to the study (Keidser et al., 2020) and thereby strengthen the results.
One limitation of a study conducted in an at-home environment is to simulate the challenging communication situations encountered outside the home. Thus, the full potential of the new Augmented Focus processing in Signia AX was not fully demonstrated in the at-home test setup. However, the results of this at-home study demonstrate that Signia AX, even when fitted remotely with no time for wearer acclimatization and (in most cases) without any fine-tuning of the devices, provides exceptionally high immediate acceptance ratings and significantly improved speech-intelligibility performance compared to the participants’ own hearing aids.
The results of this at-home study clearly indicate the benefits of hearing devices with the split processing offered by Augmented Focus: A Focus stream containing speech and a Surrounding stream, which contains background noise. Further testing – in both lab and real-life settings – are being carried out to further investigate the benefits offered by Signia AX with Augmented Focus.
Summary
Due to the limitations of the COVID-19 lockdown, a new test paradigm, based on testing in the participants’ own homes, was used to assess the new Signia AX and the Augmented Focus signal processing technology. Using a completely remote fitting and assessment process, the participants provided highly favorable ratings of their immediate acceptance of and satisfaction with Signia AX. Additionally, using the Oldenburg sentence test, a significantly better speech-in-noise performance of Signia AX was obtained in a direct comparison with the participants’ own hearing aids, showing an improvement in speech intelligibility in noise of more than 25%. Together, these results provide real world evidence that the split processing of Augmented Focus in the Signia AX provides benefits for the wearer when listening to speech, both in relatively quiet and in more challenging listening situations.
References
Best S., Serman M., Taylor B. & Høydal E.H. 2021. Augmented Focus. Signia Backgrounder. Retrieved from www.signia-library.com.
Bregman A.S. 1990. Auditory scene analysis: The perceptual organization of sound. Cambridge, MA: MIT Press.
Froehlich M., Branda E. & Freels K. 2019a. New Dimensions in Automatic Steering for Hearing Aids: Clinical and Real-world Findings. Hearing Review, 26(11), 32-37.
Froehlich M., Freels K. & Branda E. 2019b. Dynamic Soundscape Processing: Research Supporting Patient Benefit. AudiologyOnline, Article 26217. Retrieved from http://www.audiologyonline.com.
Froehlich M., Powers T.A., Branda E. & Weber J. 2018. Perception of Own Voice Wearing Hearing Aids: Why "Natural" is the New Normal. AudiologyOnline, Article 22822. Retrieved from www.audiologyonline.com.
Keidser G., Naylor G., Brungart D.S., Caduff A., Campos J., et al. 2020. The Quest for Ecological Validity in Hearing Science: What It Is, Why It Matters, and How to Advance It. Ear and Hearing, 41, 5S-19S.
Picou E.M. 2020. MarkeTrak 10 (MT10) Survey Results Demonstrate High Satisfaction with and Benefits from Hearing Aids. Seminars in Hearing, 41(1), 21-36.
Wagener K., Brand T. & Kollmeier B. 1999. Entwicklung und Evaluation eines Satztests für die deutsche Sprache. I-III: Design, Optimierung und Evaluation des Oldenburger Satztests (Development and evaluation of a sentence test for the German language. I-III: Design, optimization and evaluation of the Oldenburg sentence test). Zeitschrift für Audiologie (Audiological Acoustics), 38, 4-15.
Wagener K.C. & Brand T. 2005. Sentence intelligibility in noise for listeners with normal hearing and hearing impairment: influence of measurement procedure and masking parameters. International Journal of Audiology, 44(3), 144-156.