
A conversation starter

Engineered for conversations

Catch all sides of the conversation...

The only thing that changes is your hearing

Unleash the power of conversation
Empowering group conversations
Powered by a breakthrough technology, Signia Integrated Xperience is the world's first hearing aid with a multi-stream architecture capable of accurately pinpointing multiple moving speakers in real-time – fluidly adapting to enhance their speech and reduce background noise, even when they move around.
95% of wearers showed improved performance in a group conversation scenario.*
*Compared to RealTime Conversation Enhancement off. Jensen et al. (2023). Power the conversation with Signia Integrated Xperience and RealTime Conversation Enhancement. White Paper

Own Voice Processing 2.0
Enable your clients to contribute comfortably
Enhance client satisfaction and well-being with Signia's revolutionary patented Own Voice Processing (OVP) 2.0 technology.
Signia Assistant – Your clients' very own hearing companion
Imagine being able to help your clients to Be Brilliant every single step of their hearing journey outside your office?
Now you can – with the revolutionary live deep neural network AI of the Signia Assistant. All your clients need is their new Signia hearing aids and the Signia app.

Signia TeleCare
Benefit from our proven remote service for best-in-class trial success.
Learn more about TeleCare
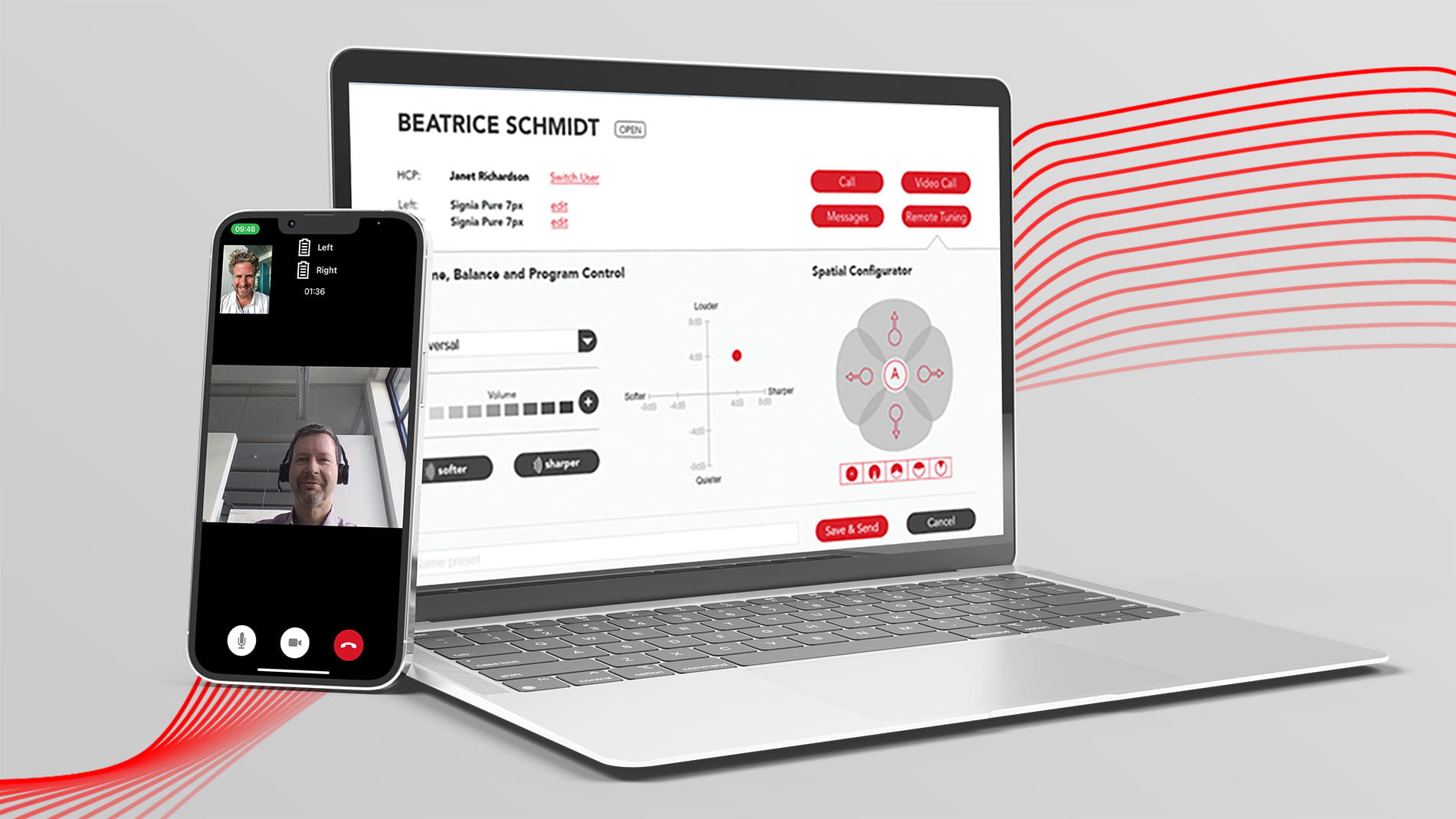
The perfect fit for perfect fittings
Connexx 9 is the digital hub for our hearing aids. Whether you’re in a consultation, programming hearing aids or offering your customers individual care, Connexx 9 supports you at every step for a fast, efficient, highly intuitive workflow.
Experience Connexx 9

Groundbreaking form factors






Be Brilliant and stay up to date
Don’t miss out!
Make your business the place to be and contact us for an appointment.
Contact us now

