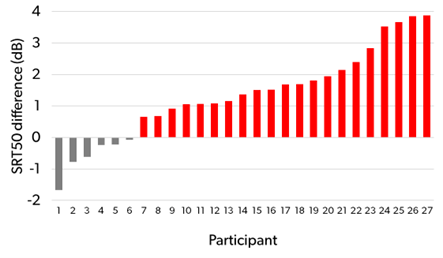
Signia Integrated Xperience (IX) con RealTime Conversation Enhancement se desarrolló para abordar una de las necesidades más importantes de los usuarios de audífonos: la capacidad de seguir y, en última instancia, contribuir a conversaciones dinámicas en grupo con ruido de fondo. En este artículo, informamos sobre un estudio en el que el rendimiento de comprensión del habla obtenido con Signia IX en una conversación de grupo ruidosa se comparó con el rendimiento proporcionado por un audífono de la competencia lanzado recientemente con una plataforma impulsada por un coprocesador de IA. Los resultados demostraron que Signia IX logró una mejora estadísticamente significativa en el umbral de recepción del habla, superando al competidor en 1,4 dB en una prueba OLSA modificada. Esta diferencia se traduce en una notable mejora del 22% en la comprensión del habla. Cabe destacar que el 77% de los 27 participantes obtuvieron mejores resultados con Signia IX que con el competidor.